
You could fit our entire engineering team in one diner booth. We serve thousands of users, ship code all day, and sleep through the night.
That's not because we replaced people with bots. It's because we built a system that lets every engineer's judgment go further.
A small team of skilled humans. Nearly fifty AI agents on the side. Same headcount, radically more output.
Our engineers still own the product, the architecture, and every merge decision. What changed is what happens around that work: the one who reads every line of code and politely points out when we've left the back door unlocked. The one who shows up every morning with a revenue report. A whole squad of specialized agents, nearly fifty of them, handling the comprehension and toil so our people can spend their time on the calls only humans should make.
I run engineering at Dib, an AI-powered home assistant. And the thing nobody warns you about a skilled tiny team in 2026 is that the bottleneck isn't writing code anymore. It's reading it. AI made authoring cheap, but review, context, and judgment don't scale by working harder. So we extended our reach with a night shift of agents that multiply what our engineers already do well.
Here's how that actually works. Grab a coffee. It's a fun one.
9:00 PM: the humans log off
We close the laptops. Dinner, kids, life. Not because the work is someone else's problem, but because we built a system where the comprehension work keeps moving without anyone staying up until 2 AM re-reading diffs.
Because at Dib, the night shift just clocked in.
The squad
We run a swarm of nearly fifty specialized AI agents. Think of them less like scripts and more like the support layer behind a company ten times our size: the reviewers, analysts, and ops watchers that let a small group of senior engineers move at a much bigger pace without burning out on grunt work.
Each one has a job and a personality to match:
- The reviewers and auditors. They read every pull request, fix broken builds, sniff for leaked secrets, double-check auth, and watch for the kind of quiet schema drift that bites you six months later.
- The analysts. Weekly digests on revenue, engagement, onboarding, competitor moves, even what people are saying about us in the app stores. It's the standup that actually has data.
- The ops watchers. Quietly minding SEO, payments, query performance, and "wait, did an environment variable change?" so we don't have to.
- The daily workers. A roster of specialists who each wake up every weekday, pick exactly one thing to improve, and propose a single tidy fix.
And here's the house rule every single one of them follows, no exceptions:
Pick one task. Open a draft. Never merge it yourself. Tell the humans in Slack.
That's it. That's the whole trick. Small, focused, reviewable changes pile up overnight like presents under a tree, and we open them over coffee.
Meet the star of the show
Of all of them, one stands out: the Pull Request Reviewer.
Every time anyone opens a pull request, human or robot, this agent springs to life. It doesn't do the boring stuff a linter already handles. It loads the exact same playbook we hand new human engineers, the living set of docs that describe how we build, and then it reviews your code against how Dib actually does things.
Then it leaves you a review like the world's most thorough senior engineer who somehow read the entire codebase last night. Inline comments on the specific lines that matter, all clearly prioritized so you know at a glance what stops the merge and what's just a nudge. It ends with a clean summary: what's good, what's risky, and a category-by-category report card.
Blockers stop the merge. Suggestions go on the pile. No ego, no Friday-afternoon grumpiness, no "looks good to me" rubber stamp at 5:59 PM.
The bottleneck on a tiny team isn't writing code anymore. It's reading it.
Here's a lightly edited example of an actual review:
Code Review — inventory search endpoint
Good implementation overall. Fast to read, clean structure. One blocking issue before this ships.
🚨 [Blocking] Cross-tenant data exposure —
app/api/inventory/search/route.ts:34This search query filters by
nameandcategorybut never scopes to the requesting team. Every other inventory endpoint wraps its query ineq(inventory.teamId, teamId)— this one doesn't. A user from Team A can currently search and retrieve items belonging to Team B by guessing category names.// current — missing teamId scope const results = await db.select() .from(inventory) .where(and( ilike(inventory.name, `%${query}%`), eq(inventory.category, category) )); // fix — add team isolation const results = await db.select() .from(inventory) .where(and( eq(inventory.teamId, teamId), ilike(inventory.name, `%${query}%`), eq(inventory.category, category) ));💡 [Suggestion] Add pagination —
route.ts:34The query has no
limit. A team with thousands of items could return the full table on a single search keystroke. Suggestlimit(20)consistent with other list endpoints.💡 [Suggestion] Validate
categoryagainst the enum —route.ts:18
categoryis read directly fromsearchParamsand passed to the query. If an invalid value is passed, Postgres will return zero results silently rather than a 400. Other endpoints usez.enum([...])here.🔒 Security: ❌ (blocking) 🚀 Performance: ⚠️ 📊 Logic: ✅
Verdict: 🚫 Changes requested — fix the teamId scope before merge. The other two are suggestions for this PR or a fast follow.
The stuff it catches that we'd miss
Regular CI is great at the things you can spell out in a config file. It's useless at the questions that actually keep you up at night:
- Does this new route lock data to the right team, the way every other route does?
- Did someone leave a "temporary" debug path that quietly skips auth? (Spoiler: temporary things live forever.)
- Are we about to log something we really, really shouldn't?
- Does this analytics event match the rest of our data, or are we about to poison a dashboard?
- Did a sneaky dependency bump just drag in a known security hole?
Those answers live in tribal knowledge and code archaeology. They don't fit in a rule file. And when humans write code faster with AI, the pull requests multiply. You cannot read exponentially more diffs by squinting harder. Something gives, unless you add a layer that reads like someone who genuinely knows your repo.
When the same mistake shows up in three PRs in a row, we don't nag people. We write the lesson down in our docs once, and the next thousand diffs inherit it automatically. Which brings me to the secret sauce.
The secret sauce: we don't program the robots, we manage them
Here's the part that surprises people. We almost never touch the agents' code to make them smarter.
Instead, we update a document.
Team norm changed? Update the doc. Want consistent enforcement across every human and every bot? Write the rule down once. Reviewer keeps missing something? Tweak the checklist.
The same documents steer the humans, the PR reviewer, and the agents. Update a rule in one place and it propagates across every reviewer and agent overnight. It's the closest thing to getting the whole system aligned instantly I've ever experienced, and it costs about as much as writing a thoughtful Slack message.
We don't program the robots. We write things down, and the whole company gets smarter overnight.
But who's in charge? (Still us.)
Before you picture the robots staging a coup, three things keep the humans firmly in the driver's seat:
- Workers only open drafts. They never merge their own work. One small fix per run, on a clearly labeled branch so we can spot them instantly. A human always decides what actually ships.
- There's an off switch. Slap a skip label on a PR and the reviewer politely sits it out. Great for the chaotic refactor we already know we're going to redo.
- It closes its own loops. When a PR is linked to a ticket, the review gets posted right back to that ticket. Nobody copy-pastes anything, ever.
And every morning, an engineering digest lands in Slack: here's what shipped overnight, here's what's risky, here are the links. It's how we wake up already in context, like a night-shift handoff note from a team that worked while we dreamed.
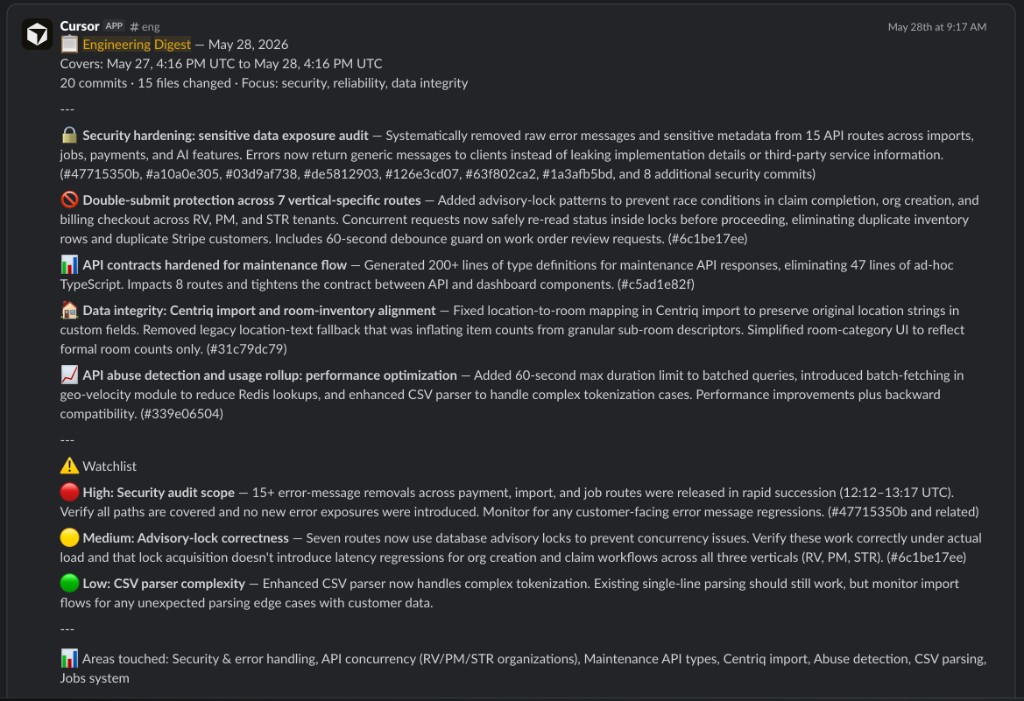
The math that still makes me grin
A team you could count on one hand, doing the work of a team many times its size. Nearly fifty agents handling the reading, the auditing, and the long tail of small fixes. A product serving thousands of people that ships all day and lets our engineers sleep at night instead of re-reading diffs at midnight.
None of this replaces engineers. We still decide what to build, how the architecture grows, and what ships. The agents don't substitute for skill. They leverage it. Every hour our people spend on product judgment is worth more because they're not drowning in comprehension work, rubber-stamp reviews, or "someone should fix this tiny thing" backlog.
That's the whole philosophy in one line: AI agents should multiply human judgment, not pretend nobody needs to think.
One more thing
Turns out we're not the only ones betting on this. We just got into the HyperAgent Founding 500, a group of teams wagering that agents are about to change how software gets built. For a tiny crew already using agents to multiply what skilled engineers can ship, that feels like coming home. We'll share what we learn as we go.
But the part I still can't get over is the simplest one. The humans clock out at 9. The agents clock in. And when we log back on, our engineers aren't behind. They're ahead, with a stack of reviewed work ready for the decisions only they can make.
If you've got a skilled tiny team and a giant to-do list, maybe it's time you gave them a night shift too.


